- Alibaba Cloud E-MapReduce.
- Amazon EMR.
- Azure HDInsight.
- Cloudera CDH.
- Google Cloud Dataproc.
- Hortonworks Data Platform.
- MapR.
- Qubole.
Keeping this in view, what are the Hadoop distributions?
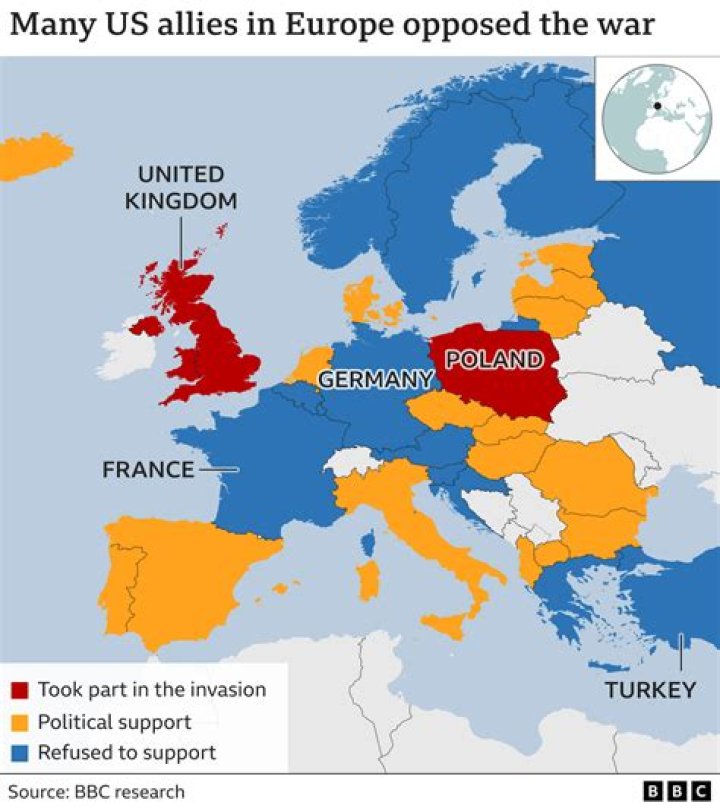
There are several distributions available, such as ones provided by EMC and Intel, as well as those provided by hardware vendors like IBM which are typically all-in-one solutions that include hardware. But the three biggest and most prevalent Hadoop distributions that exist today are Cloudera, MapR andHortonworks.
Additionally, which provides Hadoop distribution for Microsoft platform? Microsoft's Azure HDInsight platform is a cloud-only service which offers managed installations of several open source Hadoop distributions including Hortonworks, Cloudera and MapR. It integrates them with its own Azure Data Lake platform to offer a complete solution for cloud-based storage and analytics.
Correspondingly, which is the leading Hadoop provider?
IBM
How is Hadoop different from SQL?
SQL only work on structured data, whereas Hadoop is compatible for both structured, semi-structured and unstructured data. On the other hand, Hadoop does not depend on any consistent relationship and supports all data formats like XML, Text, and JSON, etc.So Hadoop can efficiently deal with big data.
What is the difference between Hadoop and Cloudera?
Major differences between Apache Hadoop and Cloudera in Big data: Apache Hadoop is the Hadoop distribution from Apacge group while Cloudera Hadoop has its own supply of Hadoop which is designed on top of Apache Hadoop, so it does not have latest release of Hadoop.What is MapR distribution?
MapR is a company that offers a Distributed Data Platform to store and analyze data of any size (typically big data) in a distributed fashion which is also linearly scalable. Anything that can be done on other distributions of Apache Hadoop can also be done on MapR. MapR also offers MapR-DB, a NoSQL database.What is Hadoop cluster?
A Hadoop cluster is a special type of computational cluster designed specifically for storing and analyzing huge amounts of unstructured data in a distributed computing environment. Typically one machine in the cluster is designated as the NameNode and another machine the as JobTracker; these are the masters.What is Hadoop architecture?
Hadoop Architecture. The Hadoop architecture is a package of the file system, MapReduce engine and the HDFS (Hadoop Distributed File System). The MapReduce engine can be MapReduce/MR1 or YARN/MR2. A Hadoop cluster consists of a single master and multiple slave nodes.What is data processing in Hadoop?
Apache Hadoop is an open source software framework used to develop data processing applications which are executed in a distributed computing environment. The processing model is based on 'Data Locality' concept wherein computational logic is sent to cluster nodes(server) containing data.What is vanilla Hadoop?
The vanilla plugin is a reference implementation which allows users to operate a cluster with Apache Hadoop. Since the Newton release Spark is integrated into the Vanilla plugin so you can launch Spark jobs on a Vanilla cluster. For cluster provisioning prepared images should be used.Which Linux is best for Hadoop?
OPERATING SYSTEM: You can install Hadoop on Linux based operating systems. Ubuntu and CentOS are very commonly used. In this tutorial, we are using CentOS. JAVA: You need to install the Java 8 package on your system.What is Hadoop and Cloudera?
Hadoop is an ecosystem of open source components that fundamentally changes the way enterprises store, process, and analyze data. CDH, Cloudera's open source platform, is the most popular distribution of Hadoop and related projects in the world (with support available via a Cloudera Enterprise subscription).Where is Hadoop used?
Hadoop is used for storing and processing big data. In Hadoop data is stored on inexpensive commodity servers that run as clusters. It is a distributed file system allows concurrent processing and fault tolerance. Hadoop MapReduce programming model is used for faster storage and retrieval of data from its nodes.Why do we need Hadoop?
Hadoop is very useful for the big business because it is based on cheap servers so required less cost to store the data and processing the data. Hadoop helps to make a better business decision by providing a history of data and various record of the company, So by using this technology company can improve its business.Does AWS use Hadoop?
Amazon Web Services uses the open-source Apache Hadoop distributed computing technology to make it easier to access large amounts of computing power to run data-intensive tasks.What are Hadoop competitors?
TOP COMPETITORS OF Apache Hadoop IN Datanyze Universe| Top Competitors | Websites | Market Share |
|---|---|---|
| Apache Spark | 4,050 | 8.37% |
| Apache Apex | 3,348 | 6.92% |
| Cloudera | 3,042 | 6.29% |
| Teradata Unified Data Architecture | 2,271 | 4.69% |
How data is stored in HDFS?
On a Hadoop cluster, the data within HDFS and the MapReduce system are housed on every machine in the cluster. Data is stored in data blocks on the DataNodes. HDFS replicates those data blocks, usually 128MB in size, and distributes them so they are replicated within multiple nodes across the cluster.Which companies are using Hadoop?
Here are top 12 hadoop technology companies expected to contribute to this fast-growing market:- Amazon Web Services. “Amazon Elastic MapReduce provides a managed, easy to use analytics platform built around the powerful Hadoop framework.
- Cloudera.
- ScienceSoft.
- Pivotal.
- Hortonworks.
- IBM.
- MapR.
- Microsoft.